揭秘阿里IT运维的基础设施,详细分析是如何支持百万级规模服务器管控?
简介:还记得这些年我们晚上爬起来重启服务器的黑历史吗?双十一期间,阿里巴巴是如何安全、稳定、高效、顺畅地管理数百万主机的?阿里巴巴运维中心技术专家宋毅首次解密阿里巴巴IT运维的基础设施,详细分析了如何支撑百万级规模服务器的管控?如何像生活中的水原煤一样做好阿里巴巴运维的基础设施平台?
客人介绍
宋健(Song Yi):阿里巴巴运维中台技术专家。经过10年的工作,他依然专注于运维领域,对大型运维系统和自动化运维有着深刻的理解和实践。 2010年加入阿里巴巴,目前负责基础运维平台。加入阿里后负责:从零开始搭建支付宝基础监控系统,推进全集团监控系统整合一、运维工具&测试PE团队。
从云效应来看2.0智能运维平台(简称:)产品,运维可以定义为两个平台,基础运维平台和应用运维平台。基础运维平台是统一的,称为,不愧是阿里巴巴IT运维的基础设施。
从10000台服务器到台服务器,再到数百万台服务器,基础设施的重要性并不是一开始就意识到的,而是逐渐被发现的。无论是运维系统的稳定性、性能还是容量,早已无法满足服务器数量和业务的快速下滑。 2015年我们升级架构,系统成功率从90%提升到99.995%,单日调用量也从1000万提升到1亿多。
全球拥有百万级服务器规模的公司屈指可数。然而,许多公司已经被业务拆分。每个企业管理自己的服务器,一个系统管理数百万台机器。应该少一些,所以我们没有太多可以学习的东西。在大多数情况下,我们都在以自己的方式前进,我们的系统也在这个过程中演变成今天的样子。
产品介绍
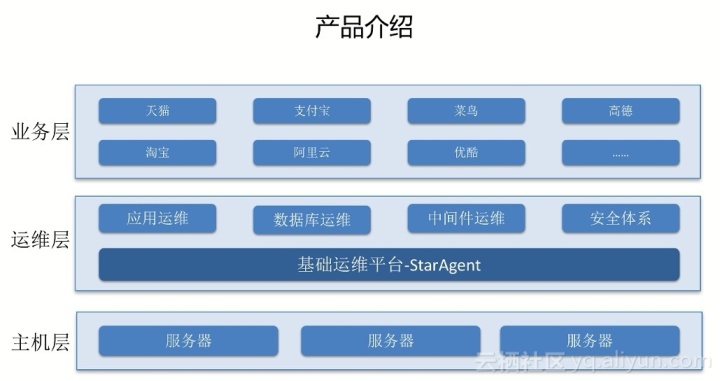
如上图,分为三层:主机层、运维层、业务层。每个团队根据分层方法进行合作。通过这张图,可以大致了解产品在组内的位置,是组内唯一的一个。官方默认代理。
应用场景
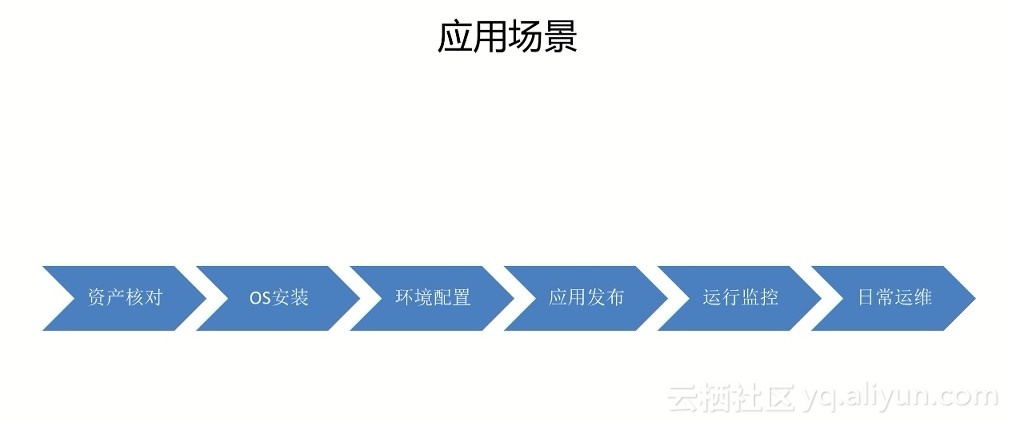
贯穿整个服务器生命周期:
产品数据

这也是我们在阿里产品的一些数据。每天晚上有上亿台服务器操作,1分钟可以操作50万台服务器,有150多个插件,管理服务器规模在百万级,Agent资源占用率也很低支持 Linux/主流发行版。
产品特点

核心功能可以概括为两大部分:控制通道和系统配置。这个和开源的//和其他配置管理产品差不多,我们做的更精细一点。

按照API、Agent细分的功能列表主要供一线开发运维朋友使用。 API 多用于底层运维系统调用。 Agent代表了可以在每台机器上直接使用的能力。
API
代理
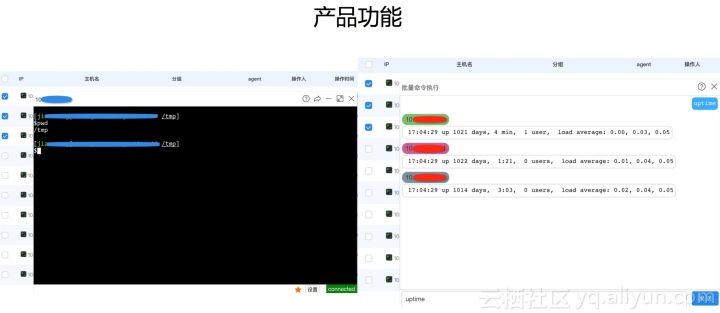
图:左边是web终端,手动发信号,可以以JS的形式嵌入到任何网页中。左边是批量执行命令的功能。首先选择一批机器,在这个页面输入的命令会发送到这批机器上。系统架构
逻辑架构
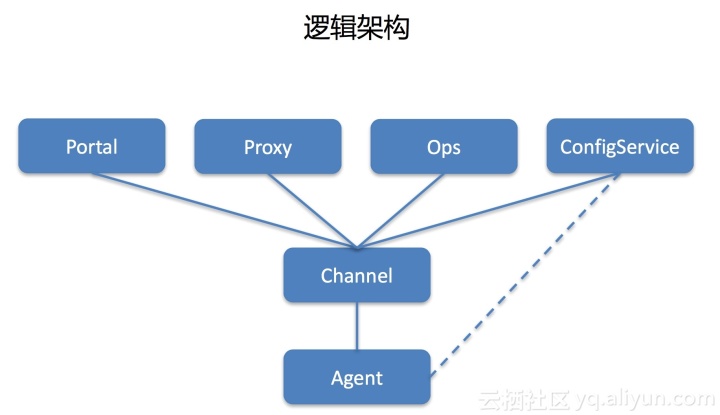
我们的系统是三层架构。每台机器安装代理,完善长连接。之后,连接代理的信息会定期上报给中心,中心会维护完整的代理和关系数据。共享两个进程:
1.代理注册
代理有一个默认配置文件。启动后,它首先连接。连接时会上报本机IP、SN等必要信息。它估计应该连接到哪个集群,并将其返回到列表中。然后和它建立一个长连接。
2.发送命令
外部系统调用代理发出命令。 proxy收到请求后,会根据目标机器找出对应关系,然后下发任务给agent,再把命令转发给agent执行。
部署框架
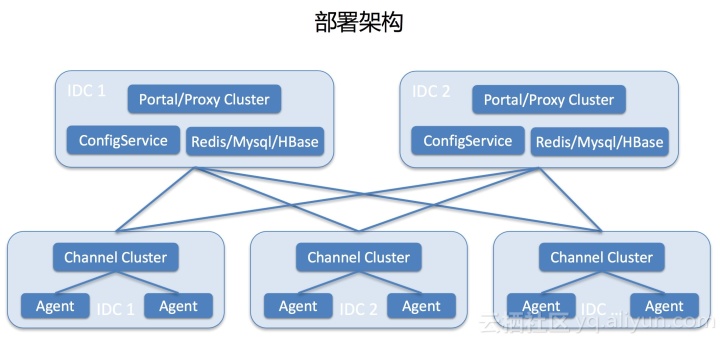
最底层是每个IDC,每个IDC会部署一个集群服务器运维技术,Agent会在其中一个随机建立一个长连接。里面是中心。中心部署了两个机房进行容灾,同时在线提供服务。其中一间机房的死亡不会影响业务。
问题与挑战
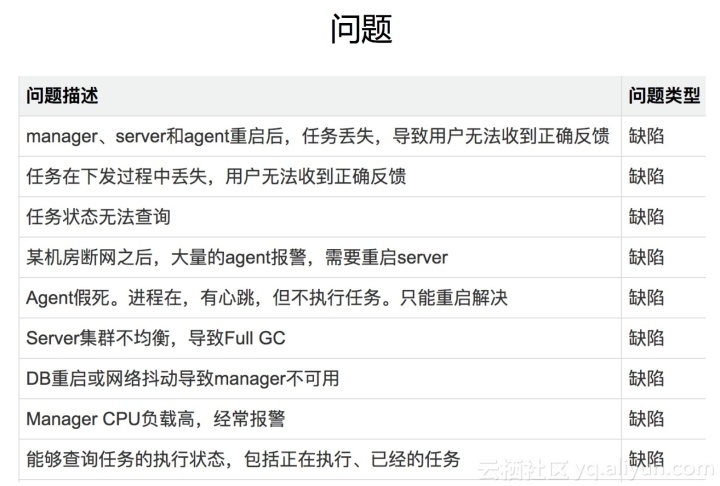
如上图:是前年在系统建设中遇到的问题:
前三个问题有点类似,主要是任务是状态引起的。 1.0 可以理解为 2.0 中的代理,相当于一直有大量系统在线 发出命令时,如果重启 //agent 的任何角色在 1.0 中,此链接上的任务将失败。比如连接到它的agent重启后会断开连接,因为链条断了,当时这个站下达的命令是拿不到结果的。重启会导致负载不均的第六个问题。假设一个IDC有10000台机器,两台机器分别连接5000台机器。重启后,10000台机器全部连接到一台机器上。
如果用户调用API发出命令失败,他们会过来让我们检查原因。有时候确实是系统问题,但是也有很多环境问题,比如机器宕机、SSH失败、负载过高等等。当磁盘满了等等,百万级的服务器有10000台机器,而每晚有百分之一的机器。回答问题的数量可想而知。那个时候,我们很郁闷。每天晚上有一半的团队成员在回答问题。晚上有一次断网演习,我们只好爬起来重启服务恢复。
如何解决这个问题?我们将问题分为两类:系统问题和环境问题。

系统问题
我们已经对系统进行了彻底的构建,采用分布式消息架构,或者以发送如下命令为例,每次都是一个任务,每个任务的状态在2.0 , 代理收到发出命令的请求后,会先记录并设置接收任务的状态,然后发送给代理。代理收到任务后,会立即响应。代理收到代理的响应后,将状态设置为执行期间,代理在执行完成后主动上报结果,代理收到结果后将状态设置为执行完成。
整个过程中proxy和agent之间的消息都有确认机制,重试会在不确认的情况下进行。这样,如果重启了任务执行过程中涉及的角色,对任务本身不会有太大影响。
2.0 集群中的机器会相互通信服务器运维技术,定期上报连接的agent数量等信息,并将接收到的信息与自己的信息结合起来。如果连接的agent太多,会手动断开最近没有任务执行的机器,通过这种方式解决负载均衡问题。中心节点与所有节点有长期连接,并存储每个连接的代理数量。当发现某个机房出现异常或容量过高时,会手动触发扩容或临时借用其他机房。扩展将被手动移除。
环境问题
在2.0中,每一层proxy//agent都有详细的错误码。通过错误码,可以直观的判断出任务错误的原因。
对于机器本身的问题,连接监控系统中的数据。任务失败后会触发环境检测,包括宕机时间、磁盘空间、负载等,如果有相应问题,API会直接返回本机。数据负责人也返回,让用户看结果就知道原因和处理谁。同时,这些诊断能力会以钉钉机器人的形式开放,让你平时可以直接在群@机器人做测试和确认。

稳定
从上面的介绍可以看出,我们可能是运维的基础设施。就像生活中的水、电和煤一样,您所有的服务器运营都非常依赖我们。当我们出现故障时,如果线上业务也出现严重故障,那么业务故障只能等待。由于服务器无法操作,无法发布和更改,因此对系统稳定性的要求非常高。在同城双机房、异地多中心容灾部署中,依赖的存储是mysql/redis/hbase,而这个存储本身就有高可用保障。单个存储故障不会影响业务,相信业内很少有系统能达到这个水平。
安全
1分钟可以操作50万台服务器,输入命令回车瞬间可以操作上万台机器。如果是恶意破坏性操作,其影响可想而知。因此实现了拦截高危指令的功能,对一些高危操作进行人工识别和拦截。整个调用链也经过加密和签名,确保第三方难以破解或篡改。针对API账号可能泄露的问题,还开发了命令映射功能,通过映射改变操作系统中的命令。例如,要执行命令,可能需要传入 a1b2。每个API账号的映射关系都不一样。
环境
连接监控数据可以解决机器停机等环境问题。前面说了,网络隔离的问题就不过多讨论了。这里我们重点关注CMDB中录入的数据与Agent采集的数据不一致的问题,主要是SN、IP等基础信息,因为你在使用的时候,首先从CMDB中提取机器信息,而然后调用我们的系统。如果不一致会直接导致调用失败,为什么会出现SN/IP不一致的问题?
CMDB 中的数据通常是由手动或其他系统触发和输入的,而 Agent 实际上是从机器上收集的。有的机器显卡上没有SN编程,有的机器网卡很多等等,环境比较复杂,各种情况都有。
这些情况都是通过构建规范来解决的,分别制定SN和IP采集规范,允许在机器上自定义机器的SN/IP,并提供采集工具配合规范。除了我们的Agent,其他所有机器信息都被收集了这个收集工具可以在所有场景中使用。当规范更新时,我们会同步更新,实现对底层业务的透明化。
原创
更多技术干货,请关注云栖社区知乎组织号:阿里云云栖社区-知乎

 售前咨询专员
售前咨询专员
