无服务器架构下的运维日志默认与运维的四个维度
在介绍运维之前,我们先简单了解一下()的概念。 由于笔者的实战经验是在AWS平台上进行的,所以本文中的指的是使用AWS构建的应用。 特点是用户不需要预先配置或管理服务器,他们只需要部署功能代码,服务会在需要时执行代码并手动扩展,从每晚几个请求到每秒数千个请求,轻松实现 FaaS (asa)。 如右图所示:
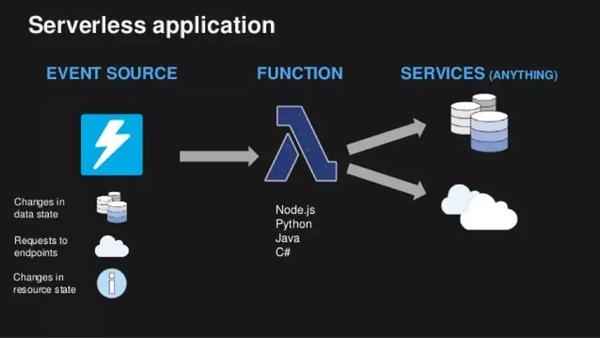
(图片来自网络)
在传统的应用程序中,开发团队不仅需要编写功能代码,还需要监控实时负载,相应地扩展应用程序,并处理一些非功能性故障(硬盘、内存等)导致的停机时间。 . 架构将开发团队从维护服务器的工作中解放出来,让他们可以更专注于功能代码(如图)。 在实际项目中,开发者只需要将功能代码打包上传到AWS,然后进行少量配置(环境变量、触发条件、显存、超时时间等)即可启动应用/服务。
以上就是架构的基本概念。 接下来笔者将从日志、指标、监控上报、容灾四个维度来介绍架构下的运维。
日志
默认情况下,应用运行时产生的日志会保存在应用服务器上。 当需要查看日志时,运维人员需要远程登录服务器获取日志信息。 这些方法操作起来略显复杂,但是当应用服务器数量增加时,查找日志的效率会严重降低,因为需要先找出导致错误信息的服务器。
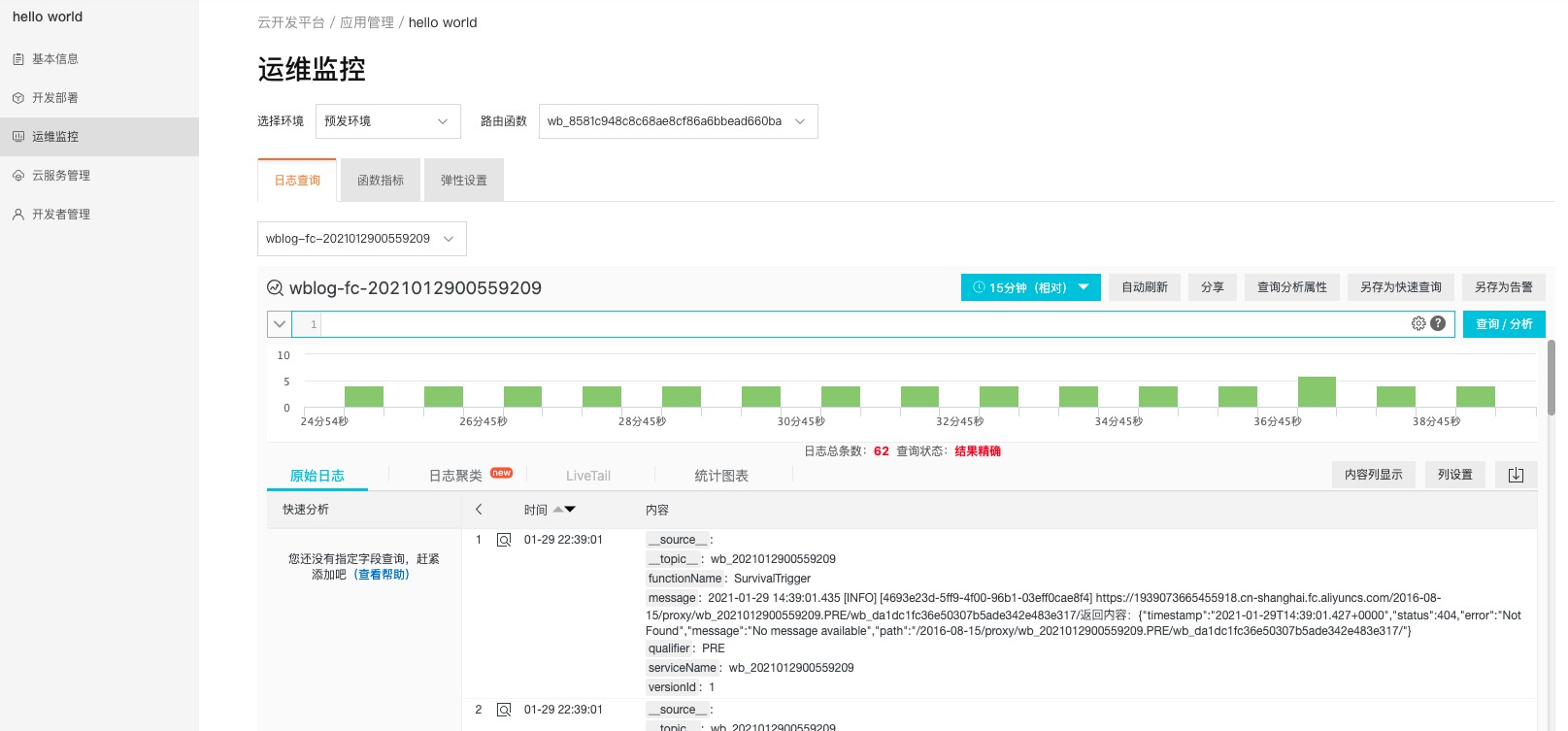
一种解决方案是 ELK(,,)。 这三个开源工具各司其职,负责日志推送和转换,作为数据库和搜索引擎,作为图形界面。 优点是易于搭建,扩展性好,免费。 但额外的代价是,独立的日志服务还需要做好全方位的监控(应用状态、硬盘、网络等),防止因为基础服务问题导致系统彻底挂掉。
AWS 无服务器架构中的日志是一种开箱即用的服务。 所有日志都手动收集到 中。 您只需要根据服务名称找到对应的日志组,即可查询搜索,无需任何配置和维护成本。 .
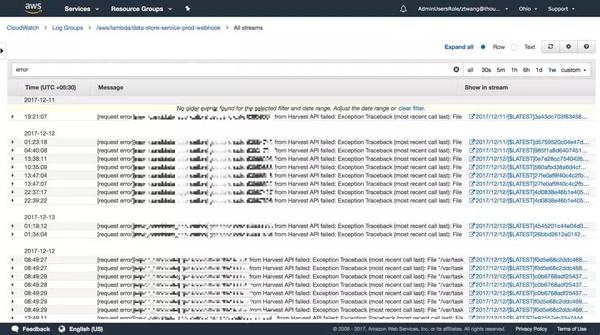
指数
通常情况下,运维工作会包括收集线上应用的运行指标服务器运维技术,反映应用的健康状况、故障率、性能、访问量、访问频率等。 下面是一个使用Boot创建的API服务的例子,起到收集指标的作用。 在默认配置中,对于每个 API,将手动收集以下指标:
其实我们可以通过实现一些来扩展/自定义 ,这里就不展开了。 有了指标数据,还需要相应的报表或仪表盘工具,方便更好的查询和展示。 您可以选择像 .
那么AWS 架构有没有提供类似的指标收集呢? 答案是肯定的,AWS人工采集了以下四个指标:
并取一段时间内的总量,两者结合得到应用的错误率,如下
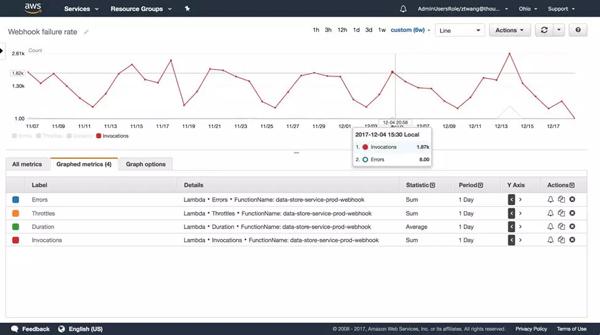
平均数用来反映一段时间内的表现。 在笔者的项目中,时长主要集中在SQL查询上。 这个数字可以反映技术人员对查询优化的有效性。 其实在实际情况中服务器运维技术,这种检查是可以在预发布环境中进行的。 这个例子只是为了便于理解。
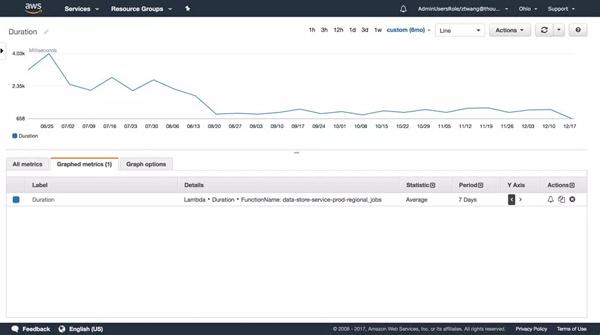
在笔者目前的项目中,并没有使用到。 默认的并发限制是1000/s,最大剂量的调用频率每分钟只有150次,远远没有超过限制。 但是,这个数据对于高并发的应用来说是非常重要的。
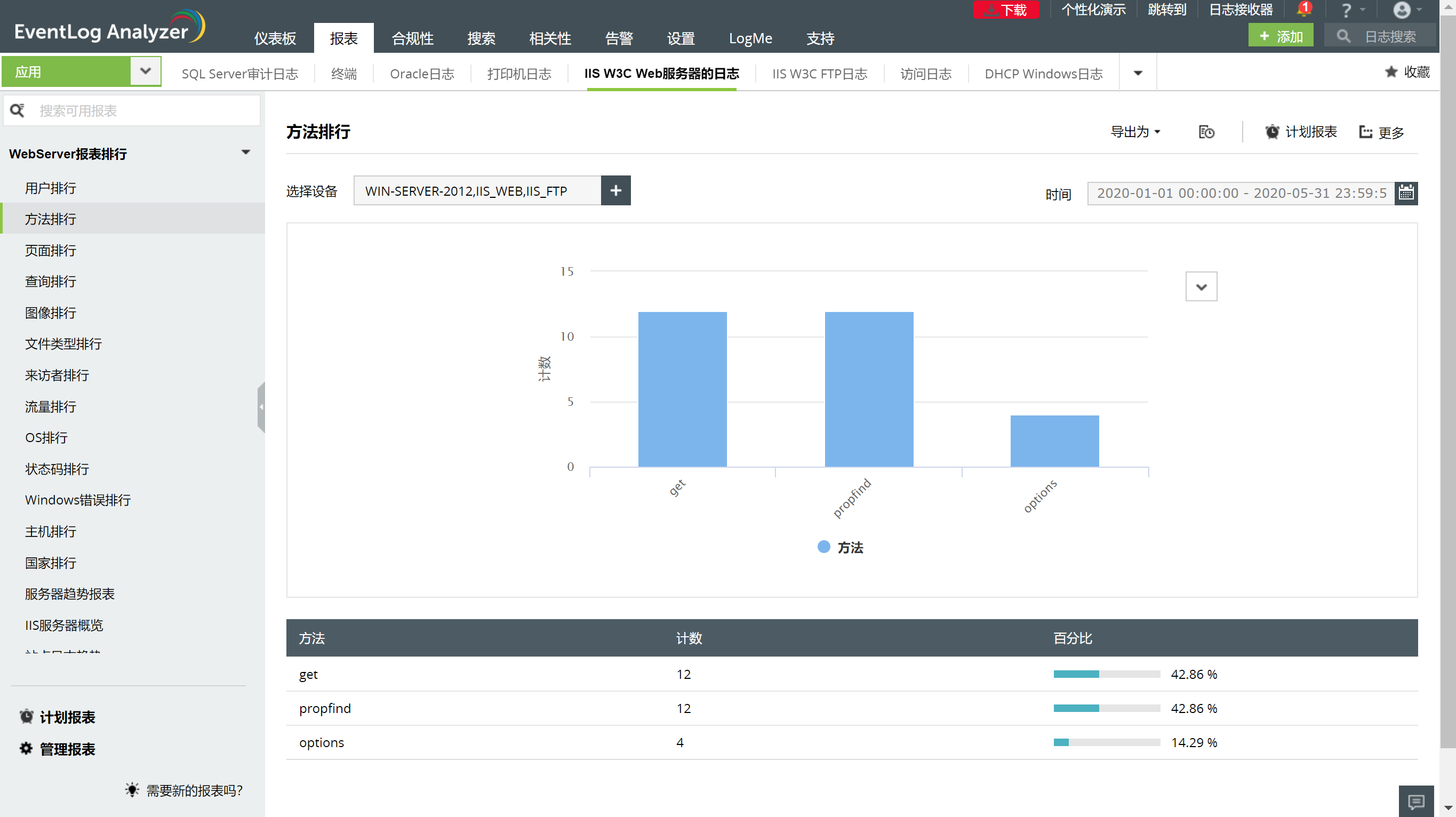
不仅开箱即用的几个指标,还有可以组合的API,可以在相应的功能代码中嵌入点数,以多种方式收集指标。 比如代码中的一、三子任务,默认提供只能体现整体的运行效率。 如果需要统计每个任务的消耗,需要使用。
监控与报告
监控的意义在于全面了解应用程序的资源使用情况、性能和运行情况。 这些数据可以用来帮助团队及时做出调整,保证应用的顺利运行。 这一般包括CPU使用率、数据传输、C盘使用率等。当突发事件导致系统不可用时,团队的响应速度往往取决于监控和报告的及时性、全面性和准确性。 如果能够根据历史数据的分析合理配置监控系统,团队甚至可以预知坏事即将发生,提前未雨绸缪,未雨绸缪。
同上,这里以一个Boot应用为例,在上一节中提到了指标数据的收集,实际上不仅可以记录其中提到的指标,还可以用来收集监控数据。 这里我们只需要搭建一个应用,在需要监控的应用中添加配置,监控数据就会通过暴露的API传递给。
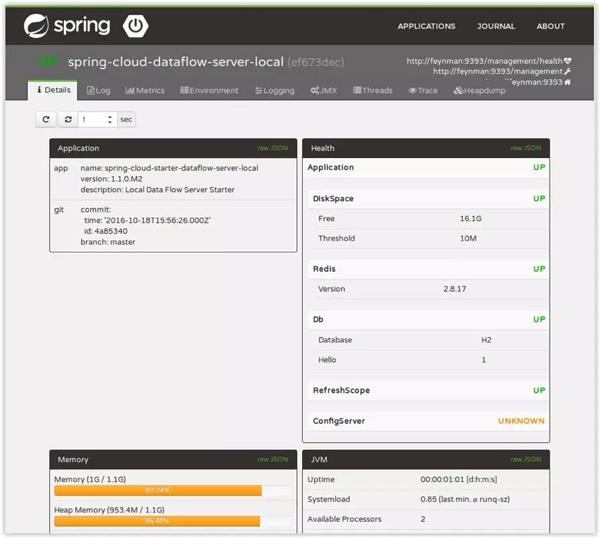
上报功能通常需要根据实际情况自行实现。 实现了Slack等第三方工具的集成。 如果只需要简单的短信提醒,实现起来并不复杂,这里就不展开了。
随着云上基础设施的普及,上述的监控和上报已经是各个平台的标配,如何实现和维护已经不是开发者操心的事情了。 运营团队可以更专注于配置优化。 去工作。
AWS默认提供了非常完善的监控数据,也允许自定义监控。 通过在创建的基础上添加一系列重要的指标,可以一目了然的看到应用的运行状态。
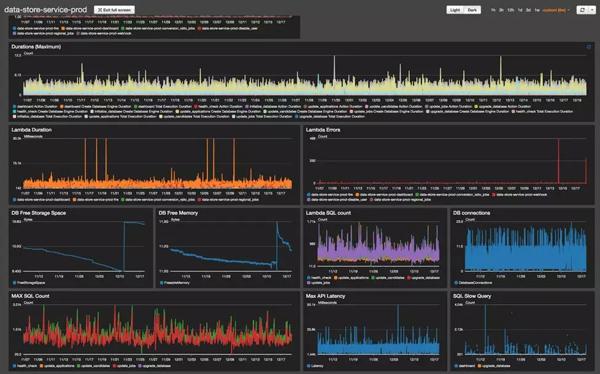
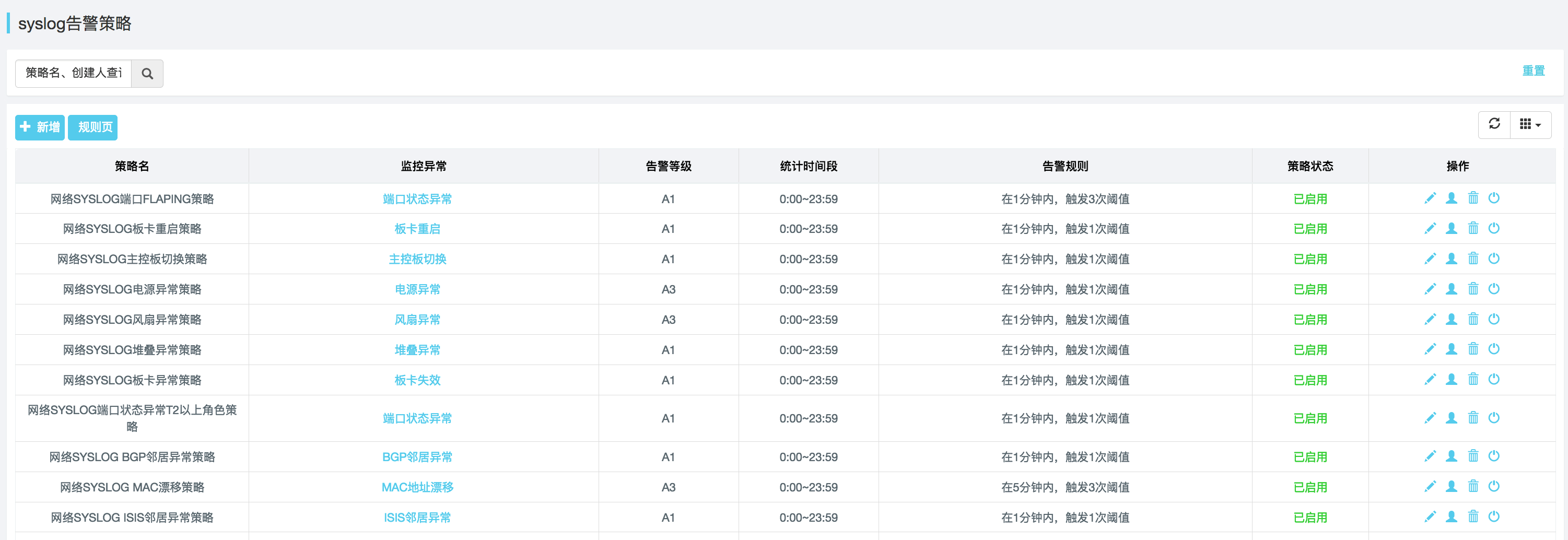
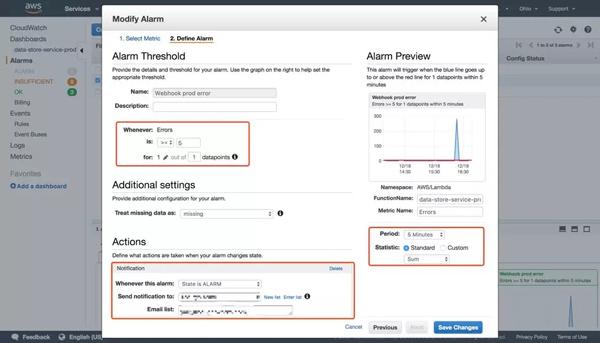
如前所述,当出现错误或性能下降时,需要根据各个关键指标的变化发送警告通知。 笔者的项目是利用AWS和提供的告警通知功能。 您只需要先选择指标,然后设置触发阈值和检测间隔。 支持 HTTP、SMS、Email 等订阅形式。 右图显示了如何设置在过去 5 分钟内错误发生超过 5 次时发送通知。
灾难备份与恢复
在系统镜像、构建工具、容器技术越来越普及的今天,容灾备份的意义很大程度上在于有效保护重要数据。 一般的做法是设置一些定时任务,将数据传输到异地的灾备中心,从数学上抵御不可抗拒的灾难。 如果数据量太大,网络传输效率跟不上,可以参考AWS用卡车拉数据的方案。

真正需要使用容灾备份的情况,笔者有限的经验还没有发生过,如果不提前做好打算,真正发生时的后果将不堪设想。 笔者项目中使用的默认开启手动备份,周期为7天。 此配置可以自动调整或写入脚本以构建基础设施。 如果真的发生了灾难,仅仅有数据备份是不够的,还要能够在应用程序运行时快速重建基础设施。 作者团队(以下简称团队)分别使用AWS和重建了数据库、网络等基础设施。 重建数据库时,通过持续集成管道,将环境变量方法传递到最近一次。 数据备份快照Id,15分钟内可重建产品环境。
总结
作者团队是10人左右的配置,采用结对编程的方式,3对,包括web端、业务层、数据层。 从确定产品原型到首次上线(MVP)需要30天,每周至少发布一次新版本。 故事的平均交付时间(,从需求确定到发布)为8天。 这样的速度显然不算快,而且如果没有运维端架构提供的支持,我们想要在交付速度上有更高的突破就难多了。
最后,让我们谈谈成本。 俗话说,放弃商业化谈技术是耍流氓。 大多数人在听到功能强大且易于使用的工具时,都会下意识地认为成本会很高。 事实上,情况并非如此。 我们粗略算了一下,选择了四核CPU、8G显存的M4服务器。 费用是每月 72 美元。 Dev 和 prod 三个环境使用相同的配置,即每月 216 美元。 事实上,每月的支出包括所有环境,大约为 20 美元。 应该注意的是,计费是基于使用的。 我们的 API 访问量大约为每月 150 万次。 可以预见,当访问量达到一定数量时,支出将等于甚至大于使用服务器的支出,而且在金额较小时优势明显。
得益于强大的AWS生态,只需极少配置或无需配置即可借助完整的应用,以极低的价格获得完整的运维功能和体验。 相比借助开源工具构建的形式,开发团队可以从繁琐的运维工作——尤其是基础工程建设中解放出来,更专注于产品本身,大大提高软件交付率和易用性,可靠性和可扩展性也相当有保证。 换来的代价是更高的迁移成本,个别功能的不多样化可能成为两难选择,底层实现原理的屏蔽也可能对开发者的学习和成长产生影响。
上一篇:服务器会选择什么操作系统呢?

 售前咨询专员
售前咨询专员
