从服务器运维的角度分析服务器智能运维(forIT)
随着互联网、5G、IoT等技术的快速发展,全球大型数据中心的数量将以3.6%的年复合增长率增长,数据中心规模将持续增长扩容,数据中心服务器规模达到10万台级别,这不仅需要更多的运维工程师,增加了企业的运维成本,也给运维带来了很大的困难和挑战工程师:如何及时发现异常设备?异常的根本原因是什么?故障能自愈吗?可以预测失败吗?性能趋势是什么?如何决定?
运维发展历程:人工运维、自动化运维、智能化运维
早期的运维工作大部分是由运维工程师手动完成的,称为人肉运维。服务器的运行状态取决于运维工程师日常的目视检查来定位和解决问题。自动化运维的出现,大大提高了检测异常设备的效率,降低了运维成本。然而,面对故障根源、故障预测、性能趋势、控制决策等方面,自动化运维显得力不从心。

2016年提出智能运维(针对IT)的概念,预计到2020年,智能运维的采用率将高达50%。从服务器运维角度分析服务器智能运维,目标是收集带外信息(配置信息、状态信息、性能信息、日志等)和带内信息(配置参数、性能信息、日志信息),机器学习用于解决运维问题,提高系统预警能力和稳定性,降低运维成本服务器运维,提高运维效率。

异常快速检测,问题准确预警
在服务器运维中,异常检测是基础。常见的监控数据有三种:状态指标、性能指标和日志数据。状态指标一般误报率较低,而传统性能指标的设置阈值往往是某个时刻产生的噪声数据,导致误报;无法对周期性变化的数据进行动态调整,经常会产生误报,大大降低了报警的准确性。日志一般是半结构化数据,根据日志级别生成告警,非常不准确服务器运维,只能检测到已知且确定性模式的异常。

云助手通过阈值实时告警,达到监控的性能指标,自动、实时、准确识别异常数据。对于日志处理,通过单条日志的语义识别和日志文件的时间序列识别,训练或维护自然语言、专家系统、神经网络、深度学习等算法,不断改进和准确检测日志异常.
智能故障处理,操作简单,维护如此简单
智能故障诊断基于异常检测。具有准确的异常检测,通过综合各种异常指标进行数据融合、过滤、加权等处理,并利用神经网络、SVM、随机森林等智能算法找出问题的根本原因,并给出问题的根源。给出问题的解决方案,让运维工程师分分钟解决问题。


智能故障预测是对设备某一部分的性能数据和状态进行动态检测,对原始数据进行数据挖掘,寻找特征数据建立数学模型,利用神经网络、SVM等智能算法进行在线/离线训练形成预测模型。在组件发生故障之前感知故障,从而避免业务停机并提高系统稳定性。
智能故障自愈是指在故障被确认或预测后,无需人工干预即可通过重启、配置或某些流程使系统恢复正常。对于故障自愈,需要维护一定的规则或标记故障。经过神经网络、SVM等算法训练,形成自愈模型,实现系统的自愈。

智能决策,感知未来发展
云助手自动化运维工具可以预测服务器的性能数据,不仅为人工预测或智能决策提供基础数据,还为业务系统提供优化建议。
云帮手基于异常检测、故障诊断、故障预测、性能预测等,通过数据模型的建立,通过神经网络、深度学习、专家系统等智能算法的不断学习,决策模型是在没有人为干预的情况下形成的。干预,智能调整服务器配置参数,进行版本基线升级/回滚等决策,实现系统性能最优、异常最少、功耗最低。
例如监控服务器运行的性能,可以在业务低时降低服务器的功耗。在集群模式下,甚至可以关闭服务器。当业务量较大时,可以将服务器性能调整到最优智能。决策。整机房/机房,功耗管理,服务器满载时,服务器功耗是否超过整机房或机柜最大功耗,超过后如何智能决策。
智能推荐,发现无限价值
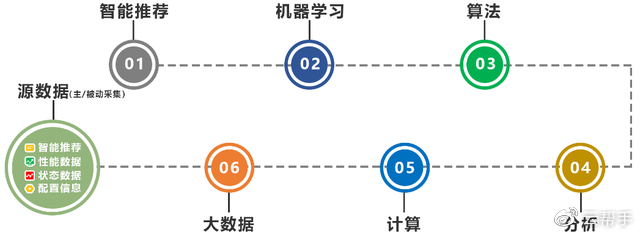
智能推荐是在平台上对大量数据进行统计、计算、分析和挖掘,建立数据模型,通过神经网络、深度学习、最小、SVM等进行分析预测,指导客户在服务器下架、备件量、扩容、减容、厂商采购等方面做出决策。比如某类服务器故障率太高,维护成本相应增加。建议将其从货架上移除。此外,由于业务增长,需要购买新的服务器。智能算法评估购买金额并提出建议。
目前,云帮手依托自身的技术优势,自主研发了一系列自动化、智能化的服务器管理软件套装,实现了从服务器巡检、配置、部署、监控、到服务器的全生命周期运维管理。故障分析。它还突破了大型基础设施智能管理平台的分布式网格架构、高性能数据采集框架、智能分析系统、无状态管理技术,实现了大型服务器全生命周期的智能管理。

 售前咨询专员
售前咨询专员
